Blog

You’re fake news!
Nas últimas eleições presidenciais dos Estados Unidos, em 2016, os maiores debates pareciam estar centrados em vazamentos de informações dos candidatos. Entre robôs no Twitter, Wikileaks e hackers russos supostamente envolvidos na desestabilização do cenário político norte americano, cidadãos tentavam entender as propostas dos candidatos ao governo. Trump, o vencedor, segue meses depois acusando veículos de “serem fake news”.
Concordando ou não com as afirmações de Trump, o fenômeno fake news, ou “notícias falsas”, tem tudo para chegar com força nas eleições brasileiras de 2018. Considerando os critérios que impulsionaram o seu crescimento nos Estados Unidos, tendo a acreditar que jornalistas e políticos brasileiros já sabem disso e se preparam para começar a se defender — ou atacar — quem considerar como seus oponentes.
Um relatório de 2012 da Pew Internet Research diz que em 2020, a quantidade de dados disponível à sociedade terá transformado completamente nossa ideia de entendimento de informações. O seu smartphone já tem acesso a grande parte do conhecimento já criado e em breve será capaz de responder qualquer pergunta mais rápido que qualquer cérebro humano. Se recusar a acreditar no que ele diz é um esforço contra evolutivo. Nossos cérebros tendem a preferir preservar energia sempre que possível, nos tornando vítimas de todo tipo de vieses, como o de confirmação e o da verdade.
6 em cada 10 americanos leem apenas o título de notícias. Até pouco tempo atrás, o trabalho de checagem de fatos era exclusivo da imprensa, a mesma responsável pela comunicação de fatos novos. O cenário tem mudado, obrigando o leitor a desempenhar parte dessa tarefa por si próprio, já que tem favorecido cada vez mais o consumo de notícias dadas por redes sociais.
Contrariando essas perspectivas negativas, pesquisadores de todo o mundo têm explorado a possibilidade de usar as mesmas tecnologias que ajudam a disseminar notícias falsas para contribuir com a análise de credibilidade dos textos compartilhados.
Pesquisas desse tipo aplicadas ao contexto brasileiro infelizmente parecem estar muito incipientes. Por isso, precisamos olhar para fora e descobrir como cientistas estrangeiros têm começado a atacar esse problema.
A Psicologia explica
A maior parte das pesquisas tem usado descobertas da Psicologia para orientar o desenvolvimento de algoritmos de inteligência artificial, especialmente na área de Natural Language Processing.
Howard S. Friedman, professor honorário em Psicologia na University of California, publicou em 1990 que, para criar uma história convincente, mentirosos falam de certas maneiras na tentativa de enganar o receptor da mensagem. Já que essas formas de expressão são intrínsecas de quando contamos histórias que sabemos não ser verdade, são bastante difíceis de serem modificadas e se torna algo passível de ser detectado via Machine Learning.
Publicações subsequentes à de Friedman indicam que podemos aprender muito sobre as emoções e motivações de alguém ao analisar as palavras usadas na comunicação. Métodos tão simples quanto contar a quantidade de palavras usadas podem ajudar a julgar se o fato comunicado é ou não verdadeiro. O uso de determinados tipos de palavras também é um bom indicador para modelos classificadores de mentiras.
Tipos de notícias falsas
Antes de automatizarmos tarefas desenvolvendo inteligência artificial, precisamos adquirir o que cientistas de dados chamam de domain knowledge. Nesse momento, temos que entender o trabalho dos jornalistas e descobrir quais são os principais tipos de notícias falsas e como cada um difere do outro.
As pesquisas já existentes indicam a existência de três principais tipos:
1. Cunho humorístico
Geralmente sites que abrigam esse tipo de artigos deixam claro que não têm a intenção de serem levados a sério. Todos os textos são baseados em premissas falsas, utilizando-se intensivamente de sarcasmo para contar sátiras e paródias do cenário atual. Por terem lido apenas o título, dificuldade de interpretação ou simplesmente quererem acreditar, leitores podem ser enganados e acabam por compartilhar artigos com amigos.
Nesta categoria podemos incluir o americano The Onion, que fala ter 4,3 trilhões de leitores diários, 572 vezes maior que a população mundial. Além disso, cita a constituição para proteger sua sátira como forma de exercício da liberdade de expressão.
2. Farsas, ou “hoaxes”
Nesta categoria abrigamos notícias onde a premissa principal tem a intenção de causar grande confusão. Algo como uma pegadinha de primeiro de abril que se espalha por milhares de pessoas via redes sociais, causando graves danos às vítimas.
Em 2016, uma das notícias falsas mais compartilhadas no Facebook dizia que um agente do FBI envolvido no vazamento de emails da então candidata à presidência Hillary Clinton havia cometido suicídio, sendo encontrado em circunstâncias que poderiam indicar também homicídio. Checagem dos fatos permitiu concluir que nada da premissa principal era verdadeiro.
3. Boatos
A distinção entre farsas e boatos não é totalmente linear, mas aqui incluímos invenções que tentam intencionalmente se passar como notícias ainda não confirmadas ou publicamente aceitas. Boatos verdadeiros ou não, sensacionalismo ou mesmo notícias da imprensa tradicional que não deixam claro quando informações ainda não foram verificadas corretamente são incluídas nesta categoria.
Quando Trump citou, em novembro de 2016, que 14% dos estrangeiros nos EUA estariam registrados para votar ilegalmente, apresentando como prova apenas uma pesquisa que recebeu diversas críticas pela metodologia usada, foi classificado como um boato por especialistas. Nesta categoria, nem sempre tudo é mentira (aqui o estudo existe e passa essa informação), mas como o jornalismo tem compromisso com a verdade, exige que dúvidas importantes sejam deixadas explícitas.
Meios de disseminação
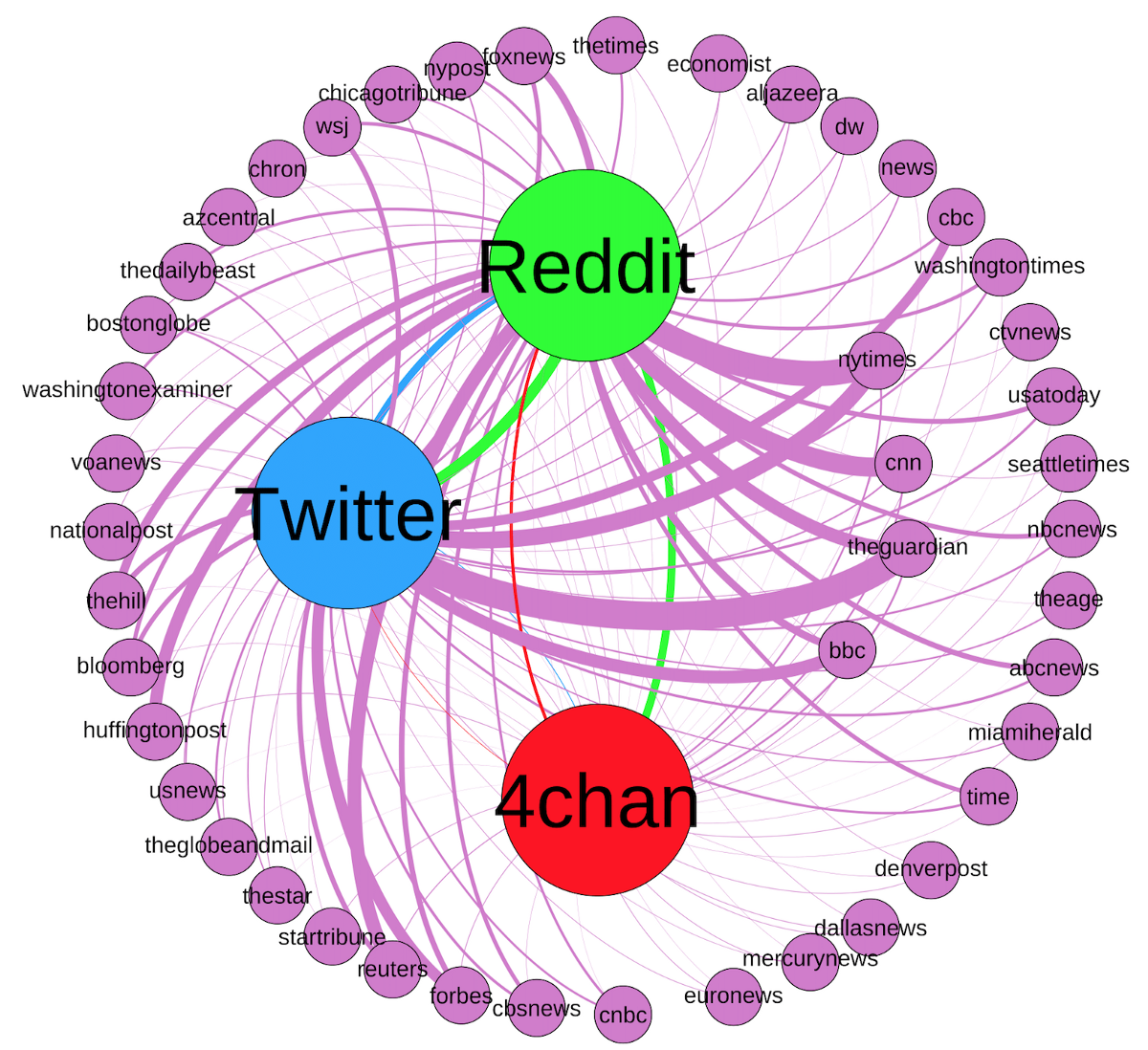
Farsas geralmente têm sua origem em sites que incentivam a anonimidade, sendo os mais proeminentes 4chan, Reddit e Twitter. Nesse tipo de comunidades, usuários encontram um ambiente com privacidade suficiente para planejar como as farsas se espalhariam por veículos da mídia tradicional. Métodos automáticos para detectar farsas dificilmente terão bons resultados analisando apenas o texto da notícia. Considerando que traçar o caminho da farsa pode levar até um tweet de alguém não conhecido publicamente, é necessário considerar que a farsa é multi plataforma.
Quando existem pessoas — jornalistas ou não — com a ânsia de compartilhar maior do que a necessidade de verificar fatos, notícias passam a ser contadas como verdade absoluta depois de algum tempo.
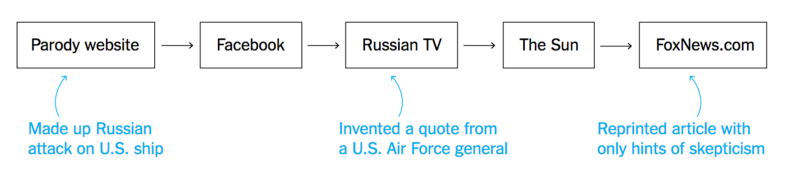
Já os boatos geralmente surgem de sites de cunho humorístico ou são criados sem grandes intenções por usuários do Facebook.
No gráfico acima, o jornal The New York Times analisa o caminho que uma determinada notícia percorreu até atingir veículos da mídia tradicional: um site de paródias inventa um ataque russo a um navio americano, recebe confirmações de usuários teoricamente envolvidos no caso via Facebook, é televisionado pela TV russa, que originou matérias de tabloides dos Estados Unidos.
Banco de dados de notícias
Já temos um problema claro e uma solução que diversos pesquisadores já apresentaram resultados satisfatórios, quando limitando o problema ao contexto dos EUA:
Usar inteligência artificial para analisar o texto de notícias e dessa forma estimar a veracidade dos fatos apresentados.
Para alcançar esse objetivo, é necessário que sejam criados bancos de dados com notícias para treinamento dos algoritmos. Victoria L. Rubin et al. apresentam uma lista de 9 pontos importantes para essa coleta de dados:
- Paridade de notícias verdadeiras e falsas — Para cada notícia verdadeira, deve existir uma semelhante, mas falsa. Dessa forma, o algoritmo consegue aprender padrões existentes apenas nas notícias falsas.
- Versão em texto das notícias — Processamento de dados desse problema inevitavelmente acontecerão a partir de um texto. Caso a notícia tenha sido dada por um discurso, idealmente a conversão já acontece antes de gerar o banco.
- Possibilidade de confirmar a verdade — Alguns tipos de notícias (como algumas fofocas de celebridades) são extremamente difíceis de serem verificadas, mesmo com dedicação e tempo de jornalistas. É preferível, neste caso, deixá-las para uma pesquisa específica.
- Homogeneidade no tamanho dos artigos — Se estiver presente no resultado final do banco, lidar com a parte matemática dos algoritmos será mais fácil.
- Homogeneidade no estilo de escrita — Classificar as notícias em gênero (e.g. artigo de opinião, notícia, anúncio inicial de notícia) e tópico (e.g. política, saúde, negócios).
- Janela de tempo bem definida para coleta — Um tópico pode facilmente mudar de estilo de escrita em 2–3 anos.
- Definir o estilo de notícia — Quando o leitor sabe que está em um veículo sensacionalista, por exemplo, pode ativar algum tipo de viés.
- Fatores pragmáticos, como custo de aquisição e disponibilidade das notícias — Idealmente, a criação do banco de dados deve custar menos do que o investimento disponível. Ainda, as notícias devem ter seus links originais para que no futuro possam verificar a veracidade do próprio banco.
- Definir idioma e cultura das notícias — Características que são extremamente válidas no idioma inglês podem não funcionar em espanhol, bem como ambos artigos, se escritos sobre os EUA, não são aplicáveis ao Brasil.
Os métodos de coleta de dados diferem entre cada um dos grupos de cientistas.
Um primeiro grupo, de psicologia, faz questionários e entrevistas pessoalmente. 50 a 100 pessoas foram entrevistas nas pesquisas de referência. Qualidade, aqui, parece mais importante que quantidade.
Um outro grupo, responsável por usar linguística para detectar fraudes em campanhas de financiamento coletivo, já foi mais generoso na quantidade: coletou 140 projetos de 3 sites diferentes, filtrados manualmente para 25.
Um terceiro, que pesquisou formas de detectar se um texto é humorístico ou não, teve à disposição 360 notícias representativas do noticiário nacional americano e canadense. Dois veículos de sátira (The Onion e The Beaver-ton) e dois de notícias legítimas (The Toronto Star e The New York Times), agregados em quatro domínios: civil, ciência, negócios e cotidiano.
Já um outro trabalhou junto de uma equipe de 5 jornalistas do Buzz Feed para checar todos os fatos presentes em cada uma das notícias dadas por nove veículos diferentes num período de quatro dias precedendo as eleições americanas, sendo três veículos de esquerda, três de direita e três mainstream. Ao todo, o corpus (banco de dados contendo os textos das notícias) contém 1.627 artigos.
Um último grupo, de uma pesquisa publicada em agosto de 2017, adotou uma abordagem diferente: usou o serviço Amazon Mechanical Turk para contratar pessoas que escreveram 240 notícias falsas. Para cada notícia falsa, os pesquisadores procuraram uma legítima, de mesmo assunto e extensão aproximada.
Resultados encontrados
Machine Learning + linguística = ❤️
Todas as pesquisas tiveram sucesso ao usar Machine Learning e linguística para detectar notícias falsas. Com exceção de um único tópico, máquinas tiveram resultados melhores que pessoas não treinadas (jornalistas). Isso permite que existam ferramentas de verificação em tempo real para ajudar leitores a tomarem a decisão de acreditar ou não em algo que estão para ler.
É difícil de detectar notícias falsas de celebridades
Talvez pelo próprio tipo de notícia comum neste tópico, onde o estilo de escrita de verdades não difere muito de mentiras, modelos de Machine Learning tiveram resultados pouco piores do que humanos não-treinados.
Legibilidade é uma das características mais importantes
Inglês correto, formal e coeso não é muito praticado por autores de notícias falsas.
Modelos são melhores quando focados em um tipo de notícia
Classificar uma notícia de política é completamente diferente de classificar esportes. Para o tópico de tecnologia e política, legibilidade é uma característica bastante importante; para celebridades, nem tanto.
Eu > eles
Notícias baseadas fundamentalmente em verdades têm grande incidência da terceira pessoa, ele(s) ou ela(s). As falsas, preferem usar a primeira pessoa (eu, nós).
Relativismo VS julgamento
Notícias verdadeiras falam de percepções e levantam dúvidas para o leitor. As falsas concluem e usam palavras de julgamento, dando certeza dos fatos que apresentam.
Citações são mais longas em notícias falsas
A extensão das citações presentes nas notícias é proporcional à chance de não ser verdadeira. Citações no The Onion são 3 vezes mais longas que em textos verídicos e comumente falam do estado emocional e motivações do interlocutor.
Existe um estilo de escrita comum entre notícias com viés político forte
Textos extremistas têm mais em comum entre si que os autores gostariam de admitir. Ao considerar elementos do texto como características do modelo de Machine Learning, algoritmos de agrupamento conseguem diferenciar notícias mainstream de outras com viés político forte (esquerda ou direita).
Nenhum veículo mainstream tem notícias completamente falsas
Geralmente as notícias falsas têm um fundo de verdade, mas os grupos pesquisados consideraram um espectro:
Fundamentalmente verdade: Fatos são comunicados precisamente. Links e imagens batem com a informação dada no artigo.
Mistura de verdades e mentiras: Parte dos elementos do artigo são comunicados de maneira adequada, mas junto de especulação ou informações sem fundamento. Classificação também usada quando o título deixa um fato subentendido e o texto não confirma.
Fundamentalmente mentira: A premissa principal do artigo não reflete uma verdade claramente confirmada.
Sem fatos: Artigos unicamente de opinião, sátiras e tirinhas.
Usando essa classificação, o grupo que teve ajuda de jornalistas para analisar a relação entre notícias com viés político e as falsas, não encontrou nenhum artigo fundamentalmente falso em veículos sem viés político forte.
Em outras palavras: é mais fácil você encontrar notícias falsas em jornais “de esquerda” ou “de direita” do que nos mainstream.
Tamanho importa
Artigos da mídia mainstream têm em média 20 parágrafos e 550 a 800 palavras. Na mídia de direita e esquerda — características correlacionadas com a presença de notícias falsas — são mais curtos nas duas métricas, geralmente tendo de 400 a 420 palavras.
Notícias falsas contém verdades
A incidência de notícias fundamentalmente falsas é aproximadamente metade do número de misturas com verdades no mesmo veículo.
Sátiras usam inglês informal
Pode parecer óbvio, mas os resultados concordam com o senso comum. Sátiras contém presença maior do que o comum de inglês informal e xingamentos.
Sátiras têm escrita característica, diferente de outras notícias (falsas ou não)
Sátiras seguem uma estrutura distinta do resto dos artigos coletados.
Enquanto notícias legítimas tendem a contar algo novo nas primeiras frases do texto, sátiras repetem a mesma informação do título. Sátiras também tendem a usar a última frase do texto como punchline, para deixar claro que o texto é, afinal, uma piada. Essa estrutura diverge bastante da pirâmide invertida, estrutura de texto comum no jornalismo.
E agora?
Apesar de todas as pesquisas estarem focadas no idioma e contexto norte americano (no máximo alguns experimentos com o britânico), pode ser que as mesmas conclusões se apliquem no Brasil. Ou não, não temos como saber sem experimentar.
Brasileiros interessados em desenvolver pesquisas e ferramentas relacionadas provavelmente vão encontrar mais dificuldades que os colegas norte-americanos. Enquanto é fácil encontrar dez algoritmos para calcular a legibilidade de textos escritos em inglês, vemos um ou dois para português brasileiro. Mas precisamos começar, criando espaços que incentivam a colaboração entre pesquisadores e jornalistas. Ferramentas desenvolvidas por um conjunto de profissionais de diversas áreas tem mais chance de dar resultados mais eficientes.
Notícias falsas já começam a afetar o nosso cotidiano — o Fabio Victor publicou um artigo em fevereiro falando de casos já tomando o tempo de cidadãos e da Justiça brasileira.
Compartilhar notícias falsas nos faz sentir bem. Quando não serve para confirmar nossas crenças pré-existentes, compartilhamos com o objetivo de reclamar da existência dos artigos. A cada clique geramos mais receita para os autores e tiramos nossa atenção do governo e do debate político, algo que muito interessa a vários atores do jogo.
Um agradecimento ao Bruno Gonçalves, o primeiro a me expor ao tema de detecção de notícias falsas por Machine Learning, e o Rodolfo Viana que fez uma pergunta que agora recebe uma resposta excessivamente longa.
Também a todos que avaliaram e criticaram o artigo antes da sua publicação: Pedro, Luciano Santa Brígida, Hanneli Tavante e Rômulo Collopy.
Leitura complementar
Se ainda não encontrou links suficientes no texto, deixo alguns artigos científicos usados como referência:
Pérez-Rosas, V., Kleinberg, B., Lefevre, A., & Mihalcea, R. (2017). Automatic Detection of Fake News, 1–10.
Pérez-Rosas, V., & Mihalcea, R. (2015). Experiments in Open Domain Deception Detection, 1–6.
Potthast, M., Kiesel, J., Reinartz, K., Bevendorff, J., & Stein, B. (2017). A Stylometric Inquiry into Hyperpartisan and Fake News, 1–10.
Rubin, V. L., Conroy, N. J., Chen, Y., & Cornwell, S. (2016). Fake News or Truth? Using Satirical Cues to Detect Potentially Misleading News., 1–11.
da Silva, N. M. R. (2017). Fake News: a revitalização do jornal e os efeitos Fact-Checking e CrossCheck no noticiário digital, 1–18.
Rubin, V. L., Chen, Y., & Conroy, N. J. (2015, August 20). Deception detection for news: Three types of fakes.
Shafqat, W., Lee, S., Malik, S., & Kim, H.-C. (2016, February 7). The Language of Deceivers: Linguistic Features of Crowdfunding Scams. http://doi.org/10.1145/2872518.2889356
Newman, M. L., Pennebaker, J. W., Berry, D. S., & Richards, J. M. (2003). Lying Words: Predicting Deception From Linguistic Styles, 1–11. http://doi.org/10.1177/0146167203251529
Friedman, H. S., & Tucker, J. S. (1990). Language and deception. In H. Giles & W. P. Robinson (Eds.), Handbook of language and social
psychology. New York: John Wiley.